
.png?width=60&height=60&name=AI%20Copilot%20logo%20(mega%20menu).png)





.png?width=600&height=600&name=Knowledge%20AI%20Feature%20image%20(2).png)







.jpg?width=600&height=600&name=Awards%20announcement%20(4).jpg)
.jpg?width=600&height=600&name=Awards%20announcement%20(3).jpg)



What makes a top-tier Natural Language Understanding Engine? First and foremost, it’s the ability to accurately identify the correct user intent. Likewise, the machine should minimize “false positive” errors where it incorrectly detects an intent that wasn’t expressed.
How to Compare NLU Engines?
While reliability and accuracy are vital, an efficient NLU engine also requires minimal training time. The ability of the NLU to learn from fewer examples, known as few-shot learning, is crucial, meaning the fewer examples needed to train the machine, the better.
A method to assess and compare NLUs is to test the trained models on new inputs they have not encountered before. For this approach, we can use a hold-out test set of randomly selected utterances where the correct intent classification is part of the dataset.
The Few-Shot Learning Paradigm
To evaluate few-shot learning, an NLU is trained on just a handful of example sentences. Naturally, fewer training sentences lead to reduced performance. As such, we want to assess whether the NLU’s performance remains practical and rule out behaviors in which performance plummets drastically.
To conduct a benchmark test that is both unbiased and rigorous, we at Cognigy utilized three independent data sources:
- HWU64 is a multi-domain dataset from Heriot-Watt University. It's focused on real-world home automation use cases, covering 64 intents across 21 domains. Here, a subset of around 11,000 user utterances was extracted and adopted. Details on the research are published in the paper “Benchmarking Natural Language Understanding Services for Building Conversational Agents” (2019).
- BANKING77 is a single-domain dataset focused on online banking queries. It comprises over 13,000 examples spanning 77 intents. Details on the research are published in the paper “Efficient Intent Detection with Dual Sentence Encoders” (2020).
- CLINC150 is a multi-domain dataset focused on popular personal assistant queries. It consists of over 20,000 user utterances, covering 150 intents across 10 domains. Details on the research are published in the paper “An Evaluation of Dataset for Intent Classification and Out-of-Scope Prediction” (2019).
Creating an Unbiased NLU Benchmark
In our tests, we compared Cognigy NLU with Microsoft CLU, Google Dialogflow, and IBM Watson platforms.
Specifically, the NLUs are trained on ten example sentences for each intent across all three datasets. We then tested them against 3080 unseen examples from Banking77, 1076 unseen examples from HWU64, and 4500 unseen examples from CLINC150 that were not included in the training data.
Both training and test data are available on GitHub for replication of the measurements. The process is visualized in the below graphic.
.png?width=212&name=Copy%20of%20Add%20a%20heading%20(4).png)
Deciphering Benchmarking Metrics
Before diving into the results, let’s quickly look at the three different benchmarking metrics (i.e., precision, recall, and F1) and what they mean.
Now imagine a fun scenario:
You have a basket of different fruits: apples, bananas, and oranges. You're trying to sort them into their respective fruit baskets.
Precision (Accuracy of Detection)
Imagine you're sorting the apples. Every time you find an apple, you put it in the apple basket. In the end, if you look in the apple basket and see only apples (no bananas or oranges), you did a great job! That's high precision. But if you find a banana in there, that means you made a mistake, and your precision is lower.
Recall (Missing any?)
Now, after you've sorted all the fruits, you look around. If you find an apple lying around that you missed putting in the apple basket, that means your recall isn't perfect. High recall means you didn't miss any apples and got them all in the right basket.
F1 (Doing Both Great!)
Let's say you get stars for doing two things: putting the right fruit in the apple basket (that's precision) and making sure you didn't leave any apples behind (that's recall). But you want a single metric that considers both these tasks together - that’s what F1 score does. F1 is the most significant score among all three as it takes a holistic approach.
All three scores range from 0 to 1, where 1 is the maximum performance where the model can detect every intent correctly.
Evaluating the Outcomes
Now that we understand the different metrics, let’s delve into the results from our October 2023 tests.
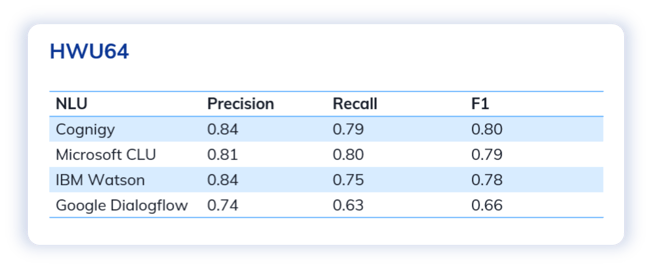
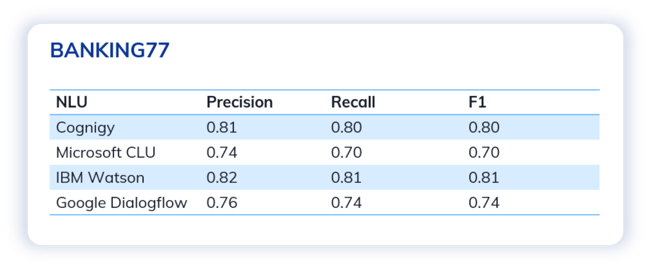
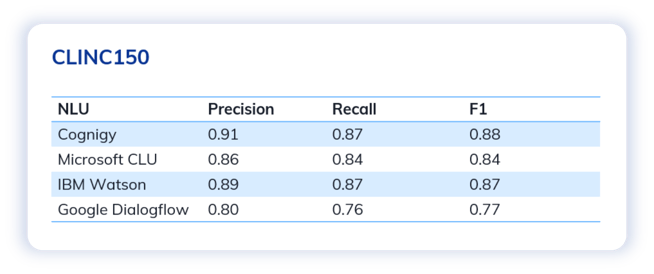
Despite the limited training sentences, Cognigy NLU achieved the leading scores in most cases across three test scenarios and benchmarking metrics.
We also observed that the performance varied across the different datasets, influenced by the complexity and challenges of the intents. For example, all models performed best in the test with the CLINC150 dataset.
That said, Cognigy NLU consistently scored 0.8 or above in almost all metrics. In contrast, other NLUs like Microsoft CLU and Google Dialogflow, appeared to experience more fluctuations in terms of performance. This showcases the extremely stable and reliable performance of Cognigy.AI, regardless of the use cases.
If you want to learn more about Cognigy NLU, you can find more details here. Interested in seeing our NLU in action? Book a demo with us today!


