
.png?width=60&height=60&name=AI%20Copilot%20logo%20(mega%20menu).png)





.png?width=600&height=600&name=Knowledge%20AI%20Feature%20image%20(2).png)











Was macht eine gute Natural Language Understanding (NLU) Engine aus? Nun, da wäre zunächst einmal die Fähigkeit, die korrekte Absicht (Intent) des Nutzers hinter einer bestimmten Eingabe zuverlässig zu erkennen. Gleichzeitig sollte die Maschine möglichst wenige „falsch-positive“ Fehler machen – also fälschlicherweise eine bestimmte Absicht zu erkennen, obwohl tatsächlich gar keine Absicht ausgedrückt wurde.
Wie kann man NLU-Engines vergleichen?
Aber Zuverlässigkeit und Genauigkeit sind nicht die einzigen Faktoren, die eine gute NLU-Engine ausmachen. Das Trainieren einer NLU kann viel Zeit und Mühe kosten. Je weniger Beispiele zum Trainieren der Maschine benötigt werden, desto besser. Diese „Few-Shot Learning“-Fähigkeiten einer NLU sollten daher unbedingt in Betracht gezogen werden.
Eine Methode zur Bewertung und zum Vergleich von NLU-Engines besteht darin, ein trainiertes Modell mit neuen Eingaben zu konfrontieren, die es bisher noch nicht gesehen hat. Ein geeigneter Ansatz hierfür ist die Festlegung eines Holdout-Testsatzes von Äußerungen durch zufällige Auswahl, wobei die korrekte Absichtsklassifikation Teil des Datensatzes ist.
Mehr Training = bessere Performance
Um die „Few-Shot Learning“-Fähigkeit einer NLU zu bewerten und mit anderen zu vergleichen, kann man so vorgehen, dass diese NLU nur mit einer Handvoll Beispielsätzen trainiert wird. Je weniger Sätze der Maschine zum Trainieren zur Verfügung stehen, desto schlechter ist die zu erwartende Performance – auf diese Weise kann man überprüfen, ob die Leistung in der Praxis auch dann noch brauchbar ist. Zudem kann man so Verhaltensweisen ausschließen, bei denen die Leistung rapide abfällt, und sich vergewissern, dass die NLU immer einen vernünftigen Standard bietet.
Um einen Benchmark-Test ohne menschliche Einflussnahme auf den Datensatz durchzuführen, verwenden wir bei Cognigy einen unabhängigen Datensatz, der von Forschern der Heriott-Watt Universität zusammengestellt wurde. Er enthält mehr als 10.000 Äußerungen zum Thema Hausautomatisierung. Details zu den Forschungen wurden in der Arbeit „Benchmarking Natural Language Understanding Services for Building Conversational Agents“ (2019) veröffentlicht. Die entsprechenden Daten sind verfügbar auf Github.
.png?width=212&name=Copy%20of%20Add%20a%20heading%20(4).png)
Bereitstellung einer neutralen Benchmark
In unserem Test haben wir die Daten von Heriott-Watt auf die NLU-Plattformen Microsoft LUIS, Google Dialogflow und IBM Watson angewendet, um sie mit Cognigy NLU zu vergleichen.
Konkret haben wir für 64 verschiedene Absichten (Intents) zufällig 10 Beispielsätze ausgewählt und diese zum Trainieren der NLUs verwendet. Anschließend haben wir 1076 Beispiele getestet, die nicht im Trainingssatz enthalten waren. Der Prozess ist in der Grafik veranschaulicht.
Um die Ergebnisse für eine unterschiedliche Anzahl von Trainingssätzen zu vergleichen, haben wir ein zweites Szenario mit 30 Beispielsätzen erstellt.
Sämtliche Ausgangsdaten sind verfügbar auf Github und können zur Replikation der Messungen verwendet werden.
Wie lauten die Ergebnisse?
Hier ist eine Übersicht zu den Ergebnissen (alle Tests wurden im August 2020 durchgeführt):
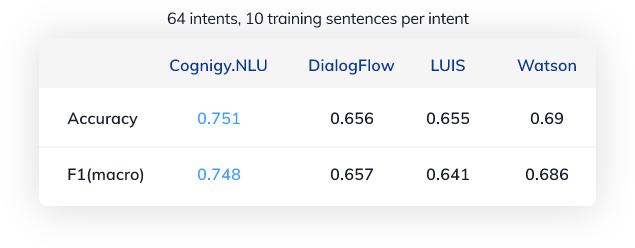
Was bedeuten die Zahlen?
Ein Genauigkeitswert (Accuracy) von 0,751 bedeutet, dass etwa 75 % der Testsätze dem korrekten Intent zugeordnet werden konnten. Da der Datensatz absichtlich so angelegt ist, dass er auch für moderne NLU-Engines eine große Herausforderung darstellt, sind 75 % ein ziemlich gutes Ergebnis. Obwohl es viele sich überschneidende und schwierige Intents gibt, ist die NLU in den meisten Fällen in der Lage, das richtige Thema, wie z. B. Musik, zu verstehen – sie kann dann nur im nächsten Schritt manchmal nicht unterscheiden, ob der Nutzer die Musik aus- oder einschalten oder ein Lied überspringen möchte. Dies ist einer der Gründe, warum Cognigy Intent-Hierarchien eingeführt hat, mit denen Intents nach seman-tischen Themen geordnet werden können, um solche hierarchischen Erkennungsprobleme zu lösen.
Wir haben den Prozess mit etwa 30 Beispielsätzen pro Intent und insgesamt 5518 Testsätzen wiederholt.
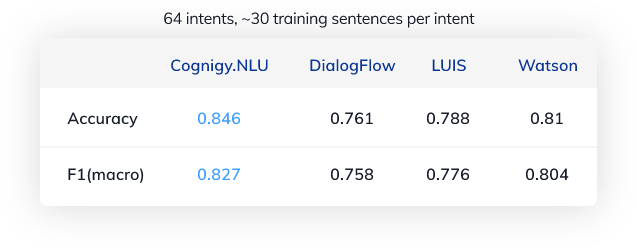
Wenig überraschend verbessert sich die Absichtserkennung mit mehr Trainingsdaten. In einem realen Szenario müsste man jedoch fast dreimal so viele Beispielsätze formulieren, um die Genauigkeit zu übertreffen, die bereits mit 10 Trainingssätzen erreicht wurde.
Ein genauer Blick in die Daten
Lassen Sie uns nun ins Detail gehen und einen genaueren Blick auf ein konkretes Beispiel aus dem Datensatz werfen.
Der Beispielsatz lautet: „are there any tornado warnings today“. Die korrekte Absicht, die alle NLU-Engines erkennen sollten, ist „weather_query“ – ein Nutzer fragt nach der Wettervorhersage.
Hier sind die einzelnen Ergebnisse für die oben erwähnten NLU-Engines:

Die Tabelle zeigt den jeweils erkannten Intent und einen entsprechenden Score für diesen Beispielsatz. Wie im vorherigen Beispiel gilt auch hier: Ein höherer Score spiegelt eine bessere Genauigkeit wider. DialogFlow, LUIS und Watson sagen den falsche Intent voraus. Und sie tun dies mit einer relativ geringen Genauigkeitseinschätzung, wodurch die Unsicherheit des Modells korrekt anzeigt wird. Die Absichtserkennung durch Cognigy ist in diesem Beispiel korrekt und auch das Vertrauen in die Genauigkeit dieser Vorhersage ist relativ hoch.
Ein Blick hinter die Daten
Obwohl die allgemeine Natur und die inhärente Zufälligkeit von Algorithmen des maschinellen Lernens uns grundsätzlich zur Vorsicht gebieten, können wir eine Interpretation der Ergebnisse in diesem Fall wagen: LUIS findet offensichtlich nicht viele Anhaltspunkte und assoziiert „today“ wahrscheinlich mit einer Kalenderabfrage. Watson und DialogFlow hingegen interpretieren den Satz in etwa so: „Gibt es heute eine Stauwarnung für mich?“ – was über weite Strecken durchaus akkurat erscheint, jedoch den Hinweis auf einen Tornado vollständig ignoriert. Ein solcher Hinweis findet sich allerdings auch nicht im Trainingssatz und müsste der NLU anderweitig bekannt sein.
Was steckt hinter Cognigys Performance?
Im Vergleich zu den Mitbewerbern erkennt die NLU von Cognigy dagegen den Tornado-Hinweis. Darüber hinaus erkennt sie nicht nur diese Wetter-Assoziation – eine Fähigkeit, ohne deren Vorhandensein die Ergebnisse der anderen NLU-Anbieter im Vergleich nicht zu erklären wären. Sie wägt außerdem die Bedeutung dieses Wortes mit konkurrierenden Signalen für andere Intents im Kontext ab, um in diesem Fall letztendlich das richtige Ergebnis zu liefern.
Die Betonung liegt allerdings auf „in diesem Fall“, da die Technologie weit von einem tiefgreifenden Konzept eines Tornados, Wetters oder Ähnlichem entfernt ist. Ihre nichtlineare Funktionsweise ist jedoch das Ergebnis eines neuronalen Netzwerks, das immer besser in der Lage ist, die in unserer Sprache kodierten Bedeutungselemente zu erfassen.
Sie würden Cognigy NLU gerne in Aktion erleben? Starten Sie Ihre kostenlose Testphase und nutzen Sie unsere Einführungs-Tutorials, um sich ein eigenes Bild von Cognigys Spitzentechnologie zu machen.



