




.png?width=60&height=60&name=AI%20Copilot%20logo%20(mega%20menu).png)



Sufficient and correct Training data is one of the most vital ingredients of every successful conversational AI venture. At the same time, the availability of real-world Intents training data is also one of the key challenges while developing conversational AI virtual agents. In this catch 22 situation, synthetic data -computer-generated data that mimics real-world phenomena - comes in extremely handy.

According to this report, “An early adopter of synthetic data, Google's Waymo self-driving car AI, is said to complete over three million miles of driving in simulation each day using synthetic data.”
But, how do we actually generate this synthetic data? In this post, I am going to demonstrate the same using the “Chatito” package for the Cognigy platform.
Introduction to training data in Cognigy
When we create virtual agents in Cognigy, we create an intent and add training data in the form of user utterances. Let’s explain this with an example of a Food ordering agent.
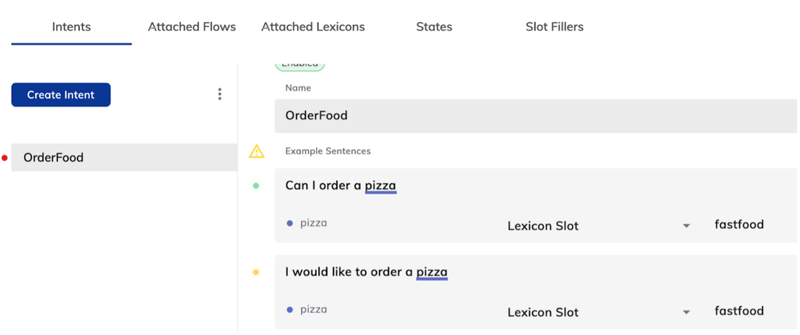
In the following example, “OrderFood” is the intent. The user has manually added various utterances and annotated them with appropriate Lexicon (1), that is, “fastfood”.
1. Lexicon: List of keyphrases
Analysis of Training data in Cognigy
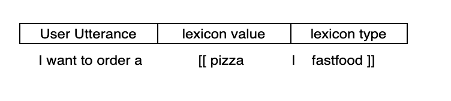
After extracting the intent from Cognigy Console, this is howThe output is a json file having training examples along with additional information like slots and lexicons. the .csv file looks like.

If you carefully analyse the training examples, the following format of user utterance is observed:
<User Utterance template> [[lexicon_value|lexicon_type]]
User Utterance Variations:
- Can I order
- I would like to order
- Place an order for
Lexicon Values:
- Pizza
- Burger
- Noodles
- Pasta
Lexicon type is “fastfood”
While we need a significant amount of training data for a good conversational experience, manually creating all of it isn’t the most efficient way out. So instead of writing text preprocessing examples manually, you can write one or several template files in a specific format. Then you can run the data generator tools which parses templates and outputs ready-to-use examples.
Training dataset adaptor Chatito
One of the useful tools for generating the synthetic training dataset for the NLU model is Chatito. Now I will walk you through the process of installation and data creation using Chatito. As a first step, install Node.js and Python. Chatito can be installed via npm:
npm install chatito
Input to Chatito is a template file where we define sample templates of user utterance. We can also provide the count of training and test data to be generated by the chatito adapter. Below is the sample template:
Template file:
Chatito Module ingests the sample template and generates training data.
The output is a json file having training examples along with additional information like slots and lexicons.
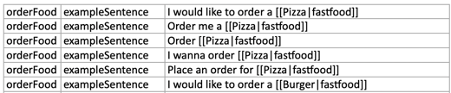
In this example, we have added an intent “orderFood” and user utterance sample. We can provide different variations of the utter utterance sample as shown above. Here all @[foodItem] values are tagged by “fastfood” lexicon.
The following command is executed to generate training examples using Chatito:
npx chatito <pathToTemplateFile> --format=default
After executing the command, the training dataset is generated. Here is the sample of training dataset: Gist.
Chatito to Cognigy training data conversion script
The chatito training data is preprocessed in accordance with the standards accepted by Cognigy via Python Script.

Here is the snippet for preprocessing the dataset:
chatito2cognigy.py
Command to run the Python Script
python chatito2cognigy.py <pathToChatitoTrainingFile> <pathToOutputCsvFile> <intentName>
Output : CSV File
This csv file can be uploaded in the Intent Section of Cognigy.
Hence by running the script, one can easily sit back and watch the tedious work done automatically.
Performance analysis
After training the model with synthetic data, we can determine the performance of the model.
The percentage of Intent Classification and Slot Filling will determine the accuracy of the model. In the early stage of virtual agent development, the threshold for interpreting the probabilities of the class is kept high. This way we can improve the NLU model. A benchmark can be created by building a test dataset with a significant number of examples (eg >100) using real-time customer data.
Here is a benchmark article, comparing F1 Score of different conversational AI providers by using open-source dataset on Github. The dataset comprises 2400 queries for each of the 7 user intents they tested.
Natural language generation
We can improvise the templates by adding an NLG component on top of Chatito. The NLG process receives the information from the chatito parser and generates a number of sentences with the same meaning. The NLG component comprises of following :
- Word order
- Word Level Grammatical Functions
- Singular/plural
- Questions
- Word Similarity and Synonyms
Thus we can generate rich conversational datasets for training. This approach provides a solution that automates the most resource-intensive task. Hence, developers need not have to do repetitive manual work.
Conclusion
The lack of a flexible dataset often limits one’s ability to explore the vast capabilities of NLU. But tools like Chatito can immensely help in generating rich synthetic datasets. Furthermore, we also discussed how we can improvise the dataset generated by Chatito so as to make it compatible with Cognigy’s standard.
Referred Links: