




.png?width=60&height=60&name=AI%20Copilot%20logo%20(mega%20menu).png)



Voice and chatbots are only as smart as we train them to be. Therefore, one of the most critical steps in the process of creating virtual agents is training the machine learning model. As humans, we often struggle to put ourselves into the mind of the machine and realize how intricate this process can be.
There are numerous ways in which the training data can be conflicting or confusing to the AI: For instance, if a user creates an intent that overlaps with an existing one. Or when example sentences are chosen in a way that weakens the recognition accuracy by diluting its discriminatory power.
Such errors and misconfigurations are hard to spot and propagate deep into the system until late in production. Even if some of these problems can be prevented through careful testing, the real challenge is to extrapolate outside of training and test whether these intents will work or not when confronted with real-world user utterances.
The approach of many popular NLUs is to test the model accuracy against real user input in production – essentially a trial & error procedure. At Cognigy, we developed a technology that is based on cross-validation and patent-pending algorithms and procedures to accurately predict model quality. As a result, users can anticipate the impact of an NLU change on the end-user experience even before changes are rolled out.
In a nutshell: Our built-in Intent Analyzer is an embedded AI service that enables bot designers to manage intents at scale and create exceptional end-user experiences with minimum training efforts.
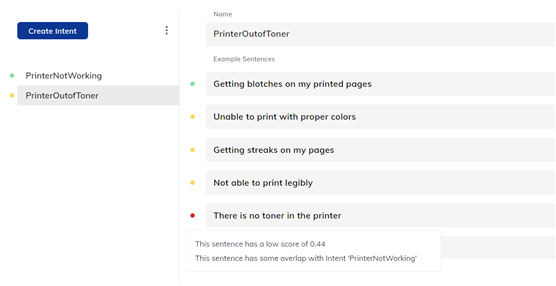
The picture above depicts how Cognigy.AI flags all the issues that creep in during development. The red dot here highlights an overlap between the example sentence of PrinterOutofToner with PrinterNotWorking Intent.
The goal: Better NLU accuracy with less training effort
Our Intent Analyzer is an embedded advisor that provides creators with immediate feedback on the quality of each example sentence, intents, or the entire NLU model to ensure that the Intents trained within agent flows are effective.
Users receive immediate traffic light feedback on the health of their model with a score ranging from 0 to 1. The score corresponds to Cognigy.AI’s level of confidence where 1 indicates that the example sentences match exactly to the intent and 0 indicates it is indistinguishable from random noise.
From a testing standpoint, this saves time because all that is required is a quick peek at the intent training menu to check the quality of the model, rather than manually conversing with the virtual agent to judge the quality of understanding.
The Intent feedback in Cognigy.AI works on three different levels:
-
Overall Intent model
-
Individual Intent
-
Individual Example Sentence
Let’s dive in to understand how smart, actionable, and granular feedback helps creators to understand the machine better.
1. Overall Intent Model
This feedback level gives a holistic view of the health of the NLU model and provides a total score on the quality.

Here a green accuracy score implies that the model is consistent and ready for user testing. However, any yellow or red traffic light in the overall model highlights critical intent design issues.
With the traffic light color feedback system, it is easy for the designers to scan the page for areas of improvement and enhance lower intent model scores by finding low scoring intents and adjusting the example sentences that also score poorly.
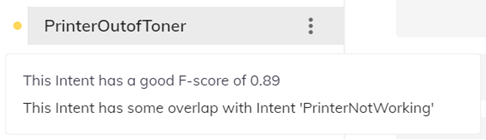
2. Individual Intent
In this level of feedback, each NLU-trained intent is given a score that informs virtual agent designers about the quality of the intent recognition in comparison to other intents.
Here the feedback window provides two pieces of vital information:
-
Intent’s overall NLU Score
-
Intents that contain overlapping example sentences
In case Intent feedback evaluates any overlap here, adjustments should be made to the example sentences contained within the intent to enhance accuracy or the overall setup of Intents should be revisited.
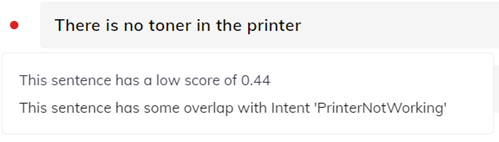
3. Individual example sentence
At this level, each example sentence is assigned a score that tells designers how useful a statement is in the context of the intent model.
The feedback window of each sample sentence contains:
-
The sentence's score in the model
-
Intents with overlapping example sentences
Better bots without trial & error
The Intent Analyzer enables creators to swiftly detect, prevent and resolve potential flaws within the training model, resulting in more accurate NLU understanding. Moreover, the top-down approach of intent feedback propels virtual agent designers from insight to action, intending to improving precision, reducing training data, and time to production.
Want to know more? Watch the Cognigy Sessions on NLU and delve deep into Cognigy.AI’s NLU capabilities.



